5 Essential Machine Learning Algorithms Explained Simply
These foundational algorithms power recommendation systems, fraud detection, medical diagnosis, and more. Learn how they work with intuitive visuals and animations.

Linear Regression, Logistic Regression, Decision Trees, Support Vector Machines, and K-Nearest Neighbors are the five essential algorithms that power most real-world machine learning applications today.
Understanding them with clear visuals and animations will dramatically improve your ability to solve data problems and build AI-powered products.
What is Linear Regression and How Does It Work?
Linear Regression is the simplest and most widely used supervised learning algorithm. It predicts continuous values by finding the straight line that best fits your data.
Imagine predicting house prices based on size. The algorithm draws a line that minimizes the error between predicted and actual prices. New predictions are made by placing the input on that line.
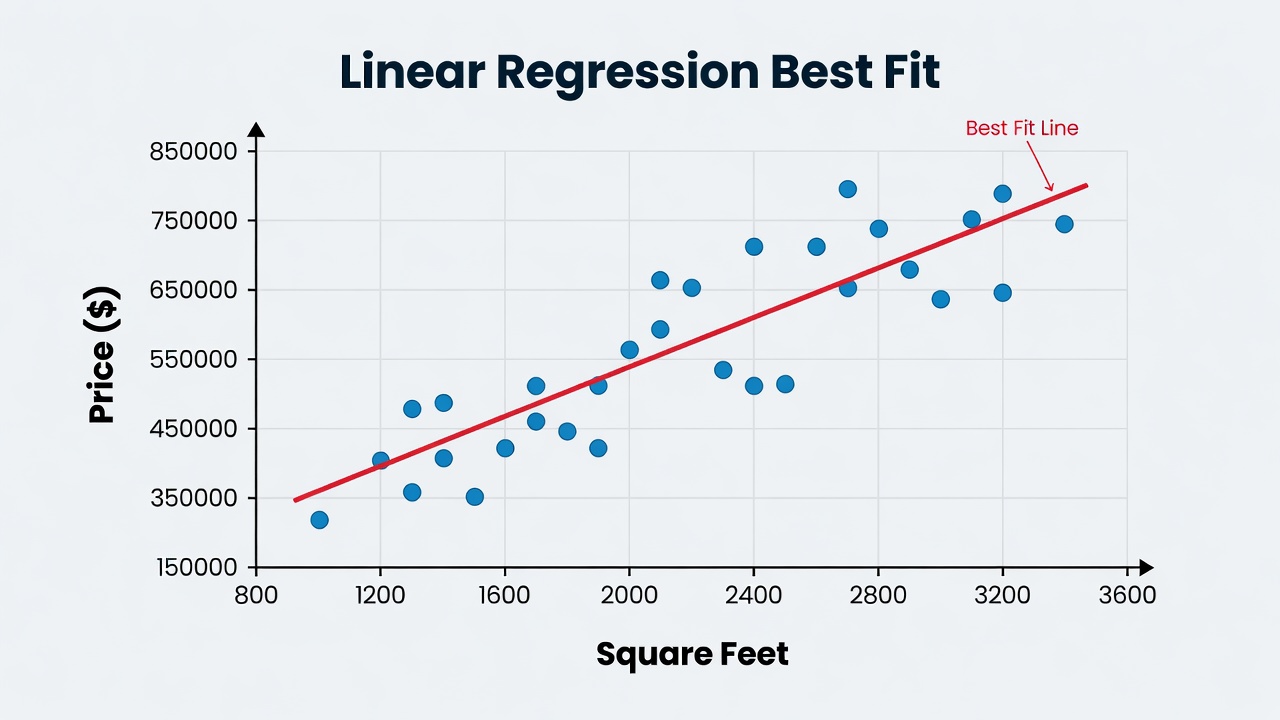
Clean scatter plot with blue data points and red best-fit line demonstrating linear regression for house price prediction
This algorithm drives forecasting in sales, stock prices, and weather prediction.
Why is Logistic Regression Used for Classification?
Despite its name, Logistic Regression is a powerful classification algorithm. It outputs probabilities between 0 and 1 using the famous sigmoid function.
In loan approval, it calculates repayment probability. Above a threshold (usually 0.5), it classifies as “Approve”; otherwise “Reject”.
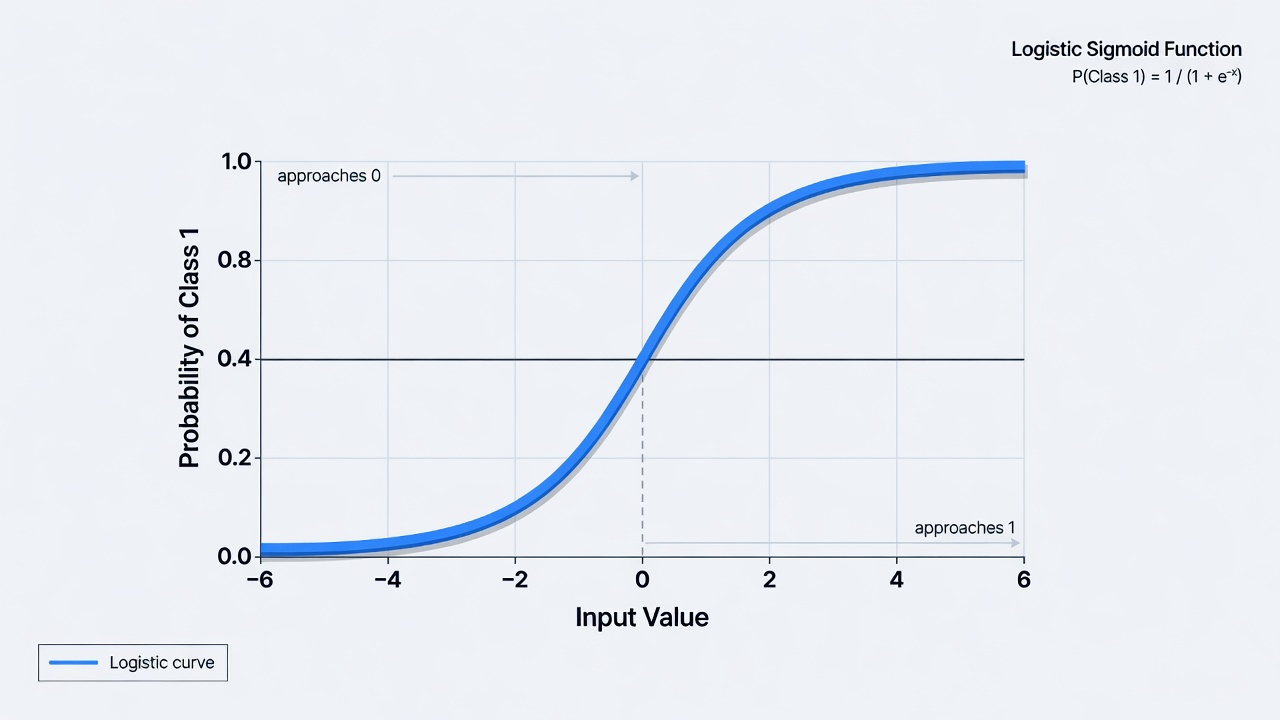
Smooth S-shaped sigmoid curve showing how logistic regression converts inputs into probabilities between 0 and 1
It excels in spam detection, fraud prevention, and medical diagnosis.
How Do Decision Trees Mimic Human Thinking?
Decision Trees are intuitive models that split data based on simple yes/no questions — exactly how humans make decisions.
For a laptop purchase: “Is it within budget?” → “Enough RAM?” → final recommendation. The tree structure makes results easy to explain to non-technical stakeholders.
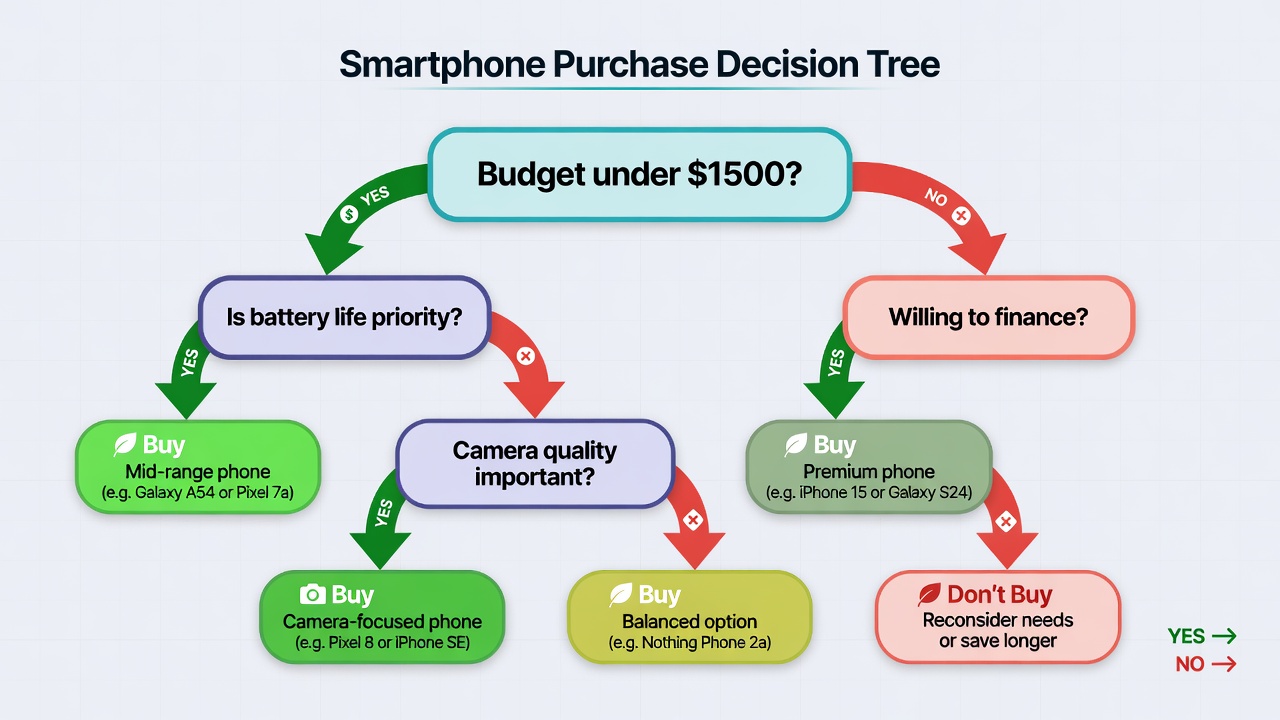
Professional decision tree diagram with root, decision nodes, and leaf outcomes showing structured decision making
Highly valued in business for transparency.
What Makes Support Vector Machines Powerful?
Support Vector Machines (SVM) find the optimal boundary (hyperplane) that separates classes while maximizing the margin between them.
This maximum-margin approach makes SVM robust, especially for image classification and text analysis.
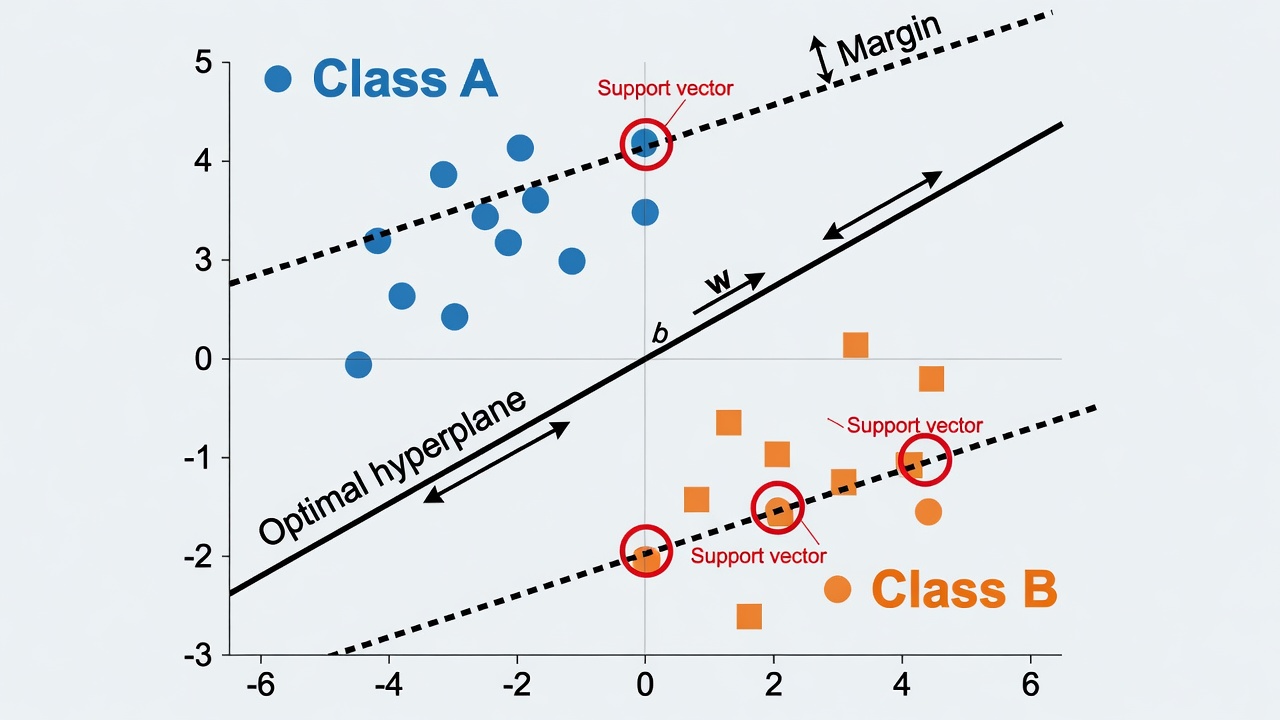
SVM illustration with hyperplanes, support vectors, and maximized margin separating two classes
How Does K-Nearest Neighbors Work?
K-Nearest Neighbors (KNN) classifies new data by looking at its closest “neighbors” and taking a majority vote.
If most nearby points belong to one class, the new point joins that class. Simple yet effective for similarity-based problems.
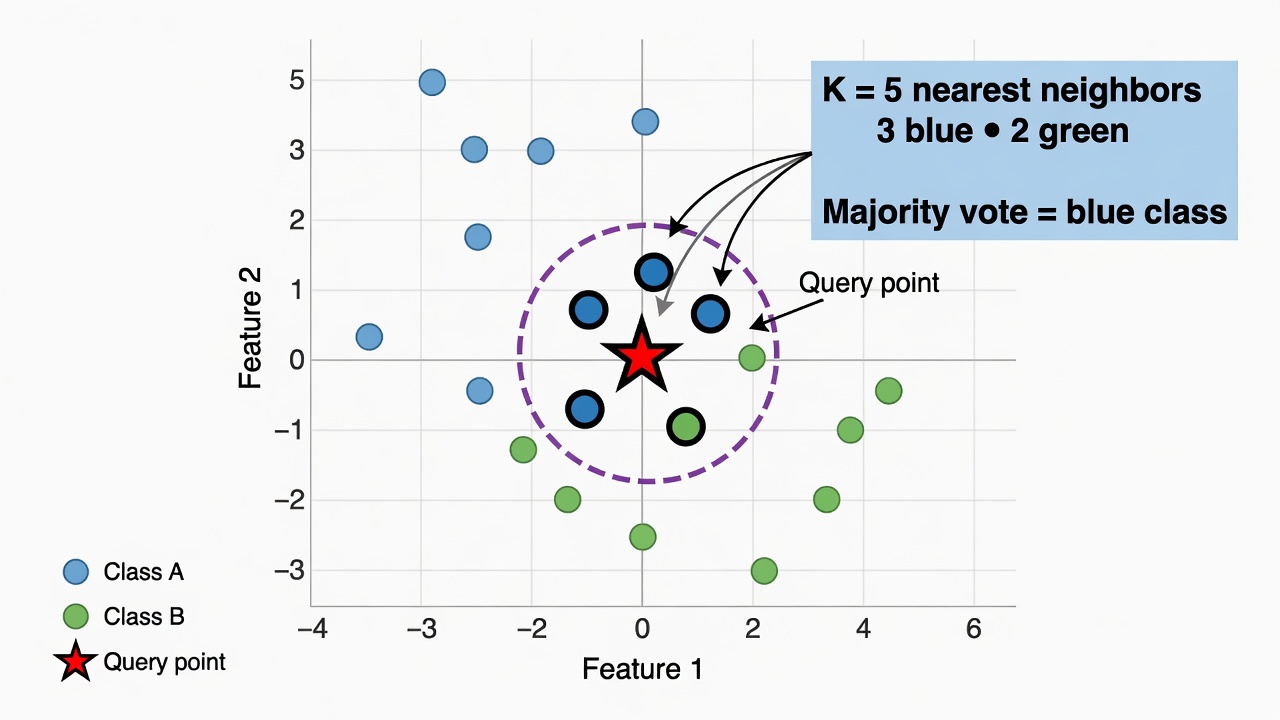
KNN visualization with expanding circle highlighting nearest neighbors and majority vote classification
Note: KNN can slow down with very large datasets due to distance calculations.
How to Choose the Right Algorithm for Your Project?
Start simple: Use Linear/Logistic Regression for quick baselines.
Choose Decision Trees when you need explainability.
Go with SVM for complex boundaries.
Use KNN when similarity matters most.
Combine them into ensembles (like Random Forests) for better performance.
Further reading & resources:
- Artificial Intelligence Hub — our full coverage of models, agents, automation, and infrastructure
- Machine Learning Concepts — scaling laws, paradigms, and why labels are the real bottleneck
- Decision Trees Guide — interpretable splitting, overfitting, and why ensembles win in practice
- Building Your First ML Model — complete step-by-step Python project with code, visuals, and video walkthroughs
Ready to implement these algorithms? Save this guide and start experimenting in Python with scikit-learn today.
What is the difference between linear and logistic regression?+
Linear regression predicts continuous values like prices, while logistic regression predicts probabilities for binary outcomes (yes/no) using a sigmoid function.
When should I use decision trees vs SVM?+
Use decision trees for interpretability and stakeholder explanations. Choose SVM when dealing with complex boundaries or high-dimensional data such as images and text.
What are the limitations of KNN?+
KNN is simple but becomes slow on large datasets because it calculates distances to every training point for each prediction.
How do I choose the right ML algorithm for my project?+
Start with simpler models like linear/logistic regression for baselines. Move to trees or SVM based on interpretability needs and data complexity.