AI AGENTS
What AI agents are, how they differ from chatbots, and why agentic AI systems represent the next major shift in AI deployment.
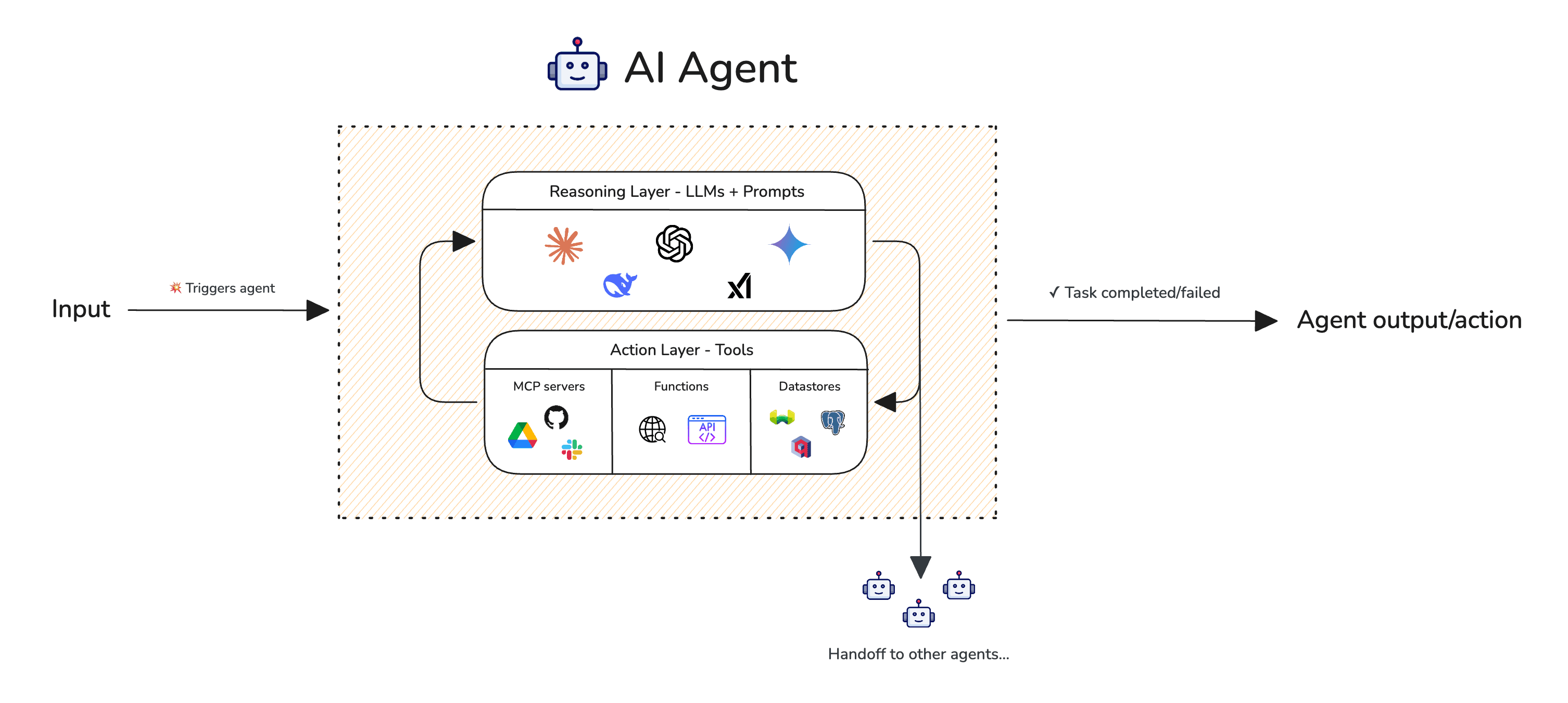
Part of: AIAn AI agent is a system that interprets a goal, plans a sequence of steps, and takes actions in the world — using tools, APIs, or other systems — until the goal is achieved or it hits a blocker.
How Agents Work
The core loop of any agent is plan, act, observe, repeat. Given a goal, the agent breaks it into sub-tasks, executes the first action, reads the result, and updates its plan accordingly. This loop continues until the task is complete or the agent determines it cannot proceed without human input.
Tool use is what makes agents meaningfully different from chatbots. An agent can run code, query a database, browse the web, write and send a file, or call an external API — and it can chain these actions across many steps. The model isn't just generating text; it's operating in an environment and responding to real feedback from that environment. Under the hood, modern agents are built on large language models whose generative AI capabilities are extended with planning and tool access.
Orchestration frameworks like LangGraph, AutoGen, and CrewAI formalize this loop, while Model Context Protocol (MCP) is emerging as a standard for how agents connect to external tools and data sources.
The Reliability Problem
Agents executing multi-step tasks have compounding error rates. If each step succeeds with 95% reliability, a 10-step task succeeds roughly 60% of the time — too low for most production use cases. This is why practical agentic deployment today looks less like a fully autonomous AI worker and more like AI completing 80% of the work with human checkpoints at high-stakes decision nodes.
The engineering challenge for the next few years is pushing per-step reliability high enough that longer autonomous chains become viable, and building the observability infrastructure to know when to interrupt.
Agents as Organizational Primitives
The more interesting medium-term implication is structural. When agents can execute complex workflows autonomously, the bottleneck in organizations shifts from execution capacity to task specification and judgment. Writing a good agent prompt or workflow specification becomes a high-leverage skill. This is where agents shade into AI automation, reshaping the future of work by moving human effort from doing tasks to defining and verifying them.
The managers and operators who understand how to decompose goals into agent-executable tasks — and how to build evaluation infrastructure to verify outputs — will have a structural advantage over those treating agents as a simple search-and-replace for human labor.
The Trust Calibration Problem
The agents that create the most value operate in domains where errors are recoverable and the cost of human review exceeds the cost of occasional mistakes. The agents that create the most risk are those given irreversible authority — sending emails, executing trades, modifying databases — without adequate human checkpoints.
Getting the trust calibration right is the core product design challenge of the agentic era. Narrow, well-scoped agents with explicit failure modes work in production. Broad, underspecified agents trusted with too much autonomy too early tend to fail in ways that are hard to debug.
Open Questions
- How do you build evaluation infrastructure for agents operating in open-ended, multi-step environments where ground truth is hard to define?
- As per-step reliability improves, what is the right handoff point between autonomous execution and human oversight — and does that threshold differ by domain?
- When agents can compose other agents, how do accountability and error attribution work across a pipeline of models with different capabilities and failure modes?
Part of the knowledge graph at The Best Blog Ever — reference definitions for ideas that matter.